Gadgets
Imiter le cerveau pour créer des assistants virtuels de type humain
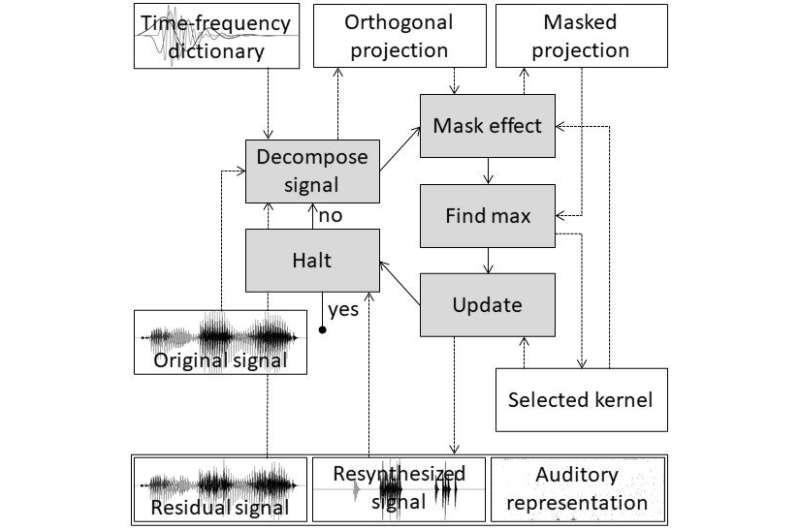
Figure 1. Une représentation de l’algorithme utilisé pour imiter la parole humaine. Légende : Pipeline de traitement de l’algorithme de poursuite de l’appariement perceptif utilisé pour dériver les représentations clairsemées auditives des signaux de parole. Les cinq principales étapes de traitement sont illustrées par des blocs gris et des flèches pleines. La première étape consiste à décomposer le signal, la deuxième à appliquer un effet de masque, la troisième à trouver le maximum, la quatrième à mettre à jour et la dernière à s’arrêter. Les informations sur le noyau sélectionné après l’étape de recherche du maximum sont utilisées pour créer la représentation auditive clairsemée, le signal resynthétisé et le signal résiduel. Crédit : Masashi Unoki du JAIST
La parole est plus qu’une simple forme de communication. La voix d’une personne transmet des émotions et une personnalité et constitue un trait unique que nous pouvons reconnaître. L’utilisation de la parole comme principal moyen de communication est une raison essentielle du développement des assistants vocaux dans les appareils intelligents et la technologie. En général, les assistants virtuels analysent la parole et répondent aux requêtes en convertissant les signaux vocaux reçus en un modèle qu’ils peuvent comprendre et traiter pour générer une réponse valide. Cependant, ils ont souvent du mal à capturer et à intégrer les complexités de la parole humaine et finissent par avoir un son très peu naturel.
Dans une étude publiée dans la revue Accès IEEELe professeur Masashi Unoki du Japan Advanced Institute of Science and Technology (JAIST) et Dung Kim Tran, étudiant en doctorat au JAIST, ont mis au point un système capable de saisir les informations contenues dans les signaux vocaux de la même manière que les humains perçoivent la parole.
« Chez l’homme, la périphérie auditive convertit les informations contenues dans les signaux vocaux d’entrée en modèles d’activité neuronale (NAP) que le cerveau peut identifier. Pour émuler cette fonction, nous avons utilisé un algorithme de poursuite d’appariement pour obtenir des représentations éparses des signaux vocaux, ou des représentations de signaux avec le minimum possible de coefficients significatifs », explique le professeur Unoki. « Nous avons ensuite utilisé des principes psychoacoustiques, tels que l’échelle de largeur de bande rectangulaire équivalente, la fonction gammachirp et les effets de masquage, pour nous assurer que les représentations auditives éparses sont similaires à celles des PAN. »
Pour tester l’efficacité de leur modèle à comprendre les commandes vocales et à générer une réponse compréhensible et naturelle, le duo a réalisé des expériences pour comparer la qualité de reconstruction du signal et les structures perceptives des représentations auditives par rapport aux méthodes conventionnelles. « L’efficacité d’une représentation auditive peut être évaluée en fonction de trois aspects : la qualité des signaux vocaux resynthétisés, le nombre d’éléments non nuls et la capacité à représenter les structures perceptuelles des signaux vocaux », explique le professeur Unoki.
Pour évaluer la qualité des signaux de parole resynthétisés, le duo a reconstruit 630 échantillons de parole prononcés par différents locuteurs. Les signaux resynthétisés ont ensuite été évalués à l’aide des scores PEMO-Q et PESQ, des mesures objectives de la qualité sonore. Ils ont constaté que les signaux resynthétisés étaient comparables aux signaux originaux. En outre, ils ont réalisé des représentations auditives de certaines phrases prononcées par 6 locuteurs.
Le duo a également testé le modèle sur sa capacité à capturer les structures vocales avec précision en utilisant une expérience de correspondance de motifs pour déterminer si les représentations auditives des phrases pouvaient correspondre à des énoncés ou des requêtes parlés par les mêmes locuteurs.
« Nos résultats ont montré que les représentations auditives éparses produites par notre méthode permettent d’obtenir des signaux resynthétisés de haute qualité avec seulement 1 066 coefficients par seconde. En outre, la méthode proposée fournit également la plus grande précision de correspondance dans une expérience de correspondance de motifs », déclare le professeur Unoki.
Des smartphones aux téléviseurs intelligents et même aux voitures intelligentes, le rôle des assistants vocaux devient de plus en plus indispensable dans notre vie quotidienne. La qualité et l’utilisation continue de ces services dépendront de leur capacité à comprendre nos accents et notre prononciation et à répondre d’une manière que nous trouvons naturelle. Le modèle développé dans cette étude pourrait contribuer à conférer des qualités humaines à nos assistants vocaux, rendant nos interactions non seulement plus pratiques mais aussi psychologiquement satisfaisantes.
Une étude explique le rôle de la transmission de la parole par l’os dans la production de la parole et l’audition.
Dung Kim Tran et al, Matching Pursuit and Sparse Coding for Auditory Representation, Accès IEEE (2021). DOI: 10.1109/ACCESS.2021.3135011
Fourni par
Institut japonais des sciences et technologies avancées
Citation:
Imiter le cerveau pour réaliser des assistants virtuels de type humain (2022, 3 février)
récupéré le 4 février 2022
à partir de https://techxplore.com/news/2022-02-mimicking-brain-human-like-virtual.html
Ce document est soumis au droit d’auteur. En dehors de toute utilisation équitable à des fins d’étude ou de recherche privée, aucune
partie ne peut être reproduite sans autorisation écrite. Le contenu est fourni à titre d’information uniquement.
Autres articles en relation:
 Samsung Galaxy Watch 4 pour prendre en charge plusieurs assistants virtuels – rapport
Samsung Galaxy Watch 4 pour prendre en charge plusieurs assistants virtuels – rapport
 Les gens font trop confiance aux assistants virtuels
Les gens font trop confiance aux assistants virtuels
 Le problème avec Alexa: quelle est la solution pour les assistants vocaux sexistes?
Le problème avec Alexa: quelle est la solution pour les assistants vocaux sexistes?
 Lorsque les assistants vocaux écoutent alors qu'ils ne devraient pas
Lorsque les assistants vocaux écoutent alors qu'ils ne devraient pas
 Rendre les assistants vocaux accessibles aux patients plus âgés
Rendre les assistants vocaux accessibles aux patients plus âgés
 Amazon et Google vont frapper le CES avec des assistants numériques
Amazon et Google vont frapper le CES avec des assistants numériques

Entreprise : 3 clés pour mettre en place une politique QSE efficace

Les startups et la GMAO

Comment choisir son patch anti-ondes ?
