Internet
Les chercheurs développent une méthode pour identifier le texte généré par ordinateur

Crédit: Petr Kratochvil / domaine public
Dans un monde d'intelligence artificielle en langage naturel beaucoup trop humain et profond, les chercheurs de l'École d'ingénierie et de sciences appliquées (SEAS) de Harvard John A. Paulson et d'IBM Research ont-ils posé les questions suivantes: Existe-t-il un meilleur moyen d'aider les utilisateurs à détecter le texte généré par l'IA?
Cette question a conduit Sebastian Gehrmann, Ph.D. candidat à SEAS, et Hendrik Strobelt, chercheur à IBM, pour développer une méthode statistique, ainsi qu'un outil interactif à accès ouvert, permettant de détecter le texte généré par l'IA.
Les générateurs de langage naturel sont formés sur des dizaines de millions de textes en ligne et imitent le langage humain en prédisant les mots qui se succèdent le plus souvent. Par exemple, les mots "have", "am" et "was" sont statistiquement les plus susceptibles de venir après le mot "I."
En utilisant cette idée, Gehrmann et Strobelt ont mis au point une méthode qui, plutôt que d’identifier les erreurs dans un texte, identifie un texte trop prévisible.
"L'idée que nous avions est que, à mesure que les modèles s'améliorent, ils vont de plus en plus pires que les humains, ce qui est détectable, à aussi bons ou meilleurs que les humains, ce qui peut être difficile à détecter avec des approches conventionnelles", a déclaré Gehrmann.
"Auparavant, vous pouviez dire par toutes les erreurs que le texte avait été généré par une machine", a déclaré Strobelt. "Désormais, ce ne sont plus les erreurs, mais plutôt l'utilisation de mots hautement probables (et quelque peu ennuyeux) qui appellent un texte généré par une machine. Avec cet outil, les humains et l'IA peuvent travailler ensemble pour détecter un faux texte."
Gehrmann et Strobelt présenteront leur recherche, qui a été co-écrite par Alexander Rush, associé en informatique à SEAS, lors de la conférence de l'Association for Computational Linguistics (ACL) du 28 juillet au 2 août.
La méthode de Gehrmann et Strobelt, connue sous le nom de GLTR, est basée sur un modèle formé sur 45 millions de textes de sites Web – la version publique du modèle OpenAI, GPT-2. Comme il utilise GPT-2 pour détecter le texte généré, le GLTR fonctionne mieux contre GPT-2, mais également contre d'autres modèles.
Voici comment ça fonctionne:
Si vous introduisez un passage de texte dans l'outil, le texte est surligné en vert, jaune, rouge ou violet, chaque couleur indiquant la prévisibilité du mot dans le contexte du mot précédent. Vert signifie que le mot était très prévisible, jaune, modérément prévisible, rouge pas très prévisible et violet signifie que le modèle n'aurait pas du tout prédit le mot.
Ainsi, un paragraphe de texte généré par GPT-2 ressemblera à ceci:

Crédit: Université de Harvard
Pour comparer, c'est un vrai New York Times article:

Crédit: Université de Harvard
Et ceci est un extrait du texte humain le plus imprévisible jamais écrit, celui de James Joyce Finnegans Wake:
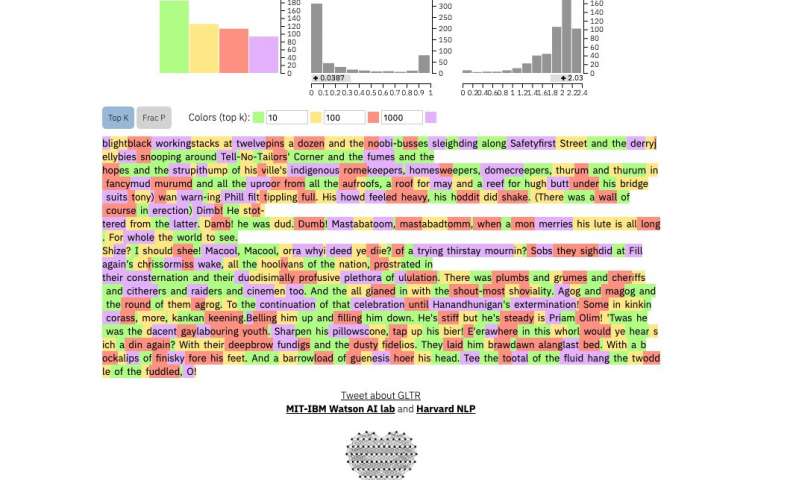
Crédit: Université de Harvard
La méthode ne vise pas à remplacer les humains lors de l'identification de faux textes, mais plutôt à soutenir leur intuition et leur compréhension. Les chercheurs ont testé le modèle avec un groupe d'étudiants de premier cycle dans un cours d'informatique SEAS.
Sans le modèle, les étudiants pourraient identifier environ 50% du texte généré par l'IA. Avec la superposition de couleurs, les étudiants ont pu identifier 72%.
Gehrmann et Strobelt disent qu’avec un peu de formation et d’expérience avec le programme, leur nombre pourrait encore s’améliorer.
"Notre objectif est de créer des systèmes de collaboration entre l'homme et l'IA", a déclaré Gehrmann. "Cette recherche a pour but de donner aux humains plus d'informations afin qu'ils puissent prendre une décision éclairée sur ce qui est réel et ce qui est faux."
Architecture de reseau neuronal a convolution multi-representative pour la classification de texte
Citation:
Des chercheurs développent une méthode d'identification du texte généré par ordinateur (26 juillet 2019)
récupéré le 27 juillet 2019
à partir de https://techxplore.com/news/2019-07-method-computer-generated-text.html
Ce document est soumis au droit d'auteur. Mis à part toute utilisation équitable à des fins d’étude ou de recherche privée, aucun
partie peut être reproduite sans autorisation écrite. Le contenu est fourni seulement pour information.
Sommaire
Les offres de produits Hi-tech en rapport avec cet article
Autres articles en relation:
 Les scientifiques développent une méthode pour détecter les fausses nouvelles
Les scientifiques développent une méthode pour détecter les fausses nouvelles
 Les chercheurs proposent une méthode pour équilibrer l'expérience utilisateur et le coût du cloud
Les chercheurs proposent une méthode pour équilibrer l'expérience utilisateur et le coût du cloud
 Les chercheurs développent un outil pour mieux gérer les onglets du navigateur
Les chercheurs développent un outil pour mieux gérer les onglets du navigateur
 Des chercheurs développent un système d'alerte précoce pour lutter contre la désinformation en ligne
Des chercheurs développent un système d'alerte précoce pour lutter contre la désinformation en ligne
 Les chercheurs développent des moyens de rendre l'IoT vraiment omniprésent
Les chercheurs développent des moyens de rendre l'IoT vraiment omniprésent
 L’outil navigateur vise à aider les chercheurs à identifier les sites Web malveillants, le code
L’outil navigateur vise à aider les chercheurs à identifier les sites Web malveillants, le code
 Des chercheurs développent un système d’alerte d’urgence alimenté par smartphone
Des chercheurs développent un système d’alerte d’urgence alimenté par smartphone
 Des chercheurs développent une caméra ultra-compacte de la taille d’un grain de sel
Des chercheurs développent une caméra ultra-compacte de la taille d’un grain de sel

Entreprise : 3 clés pour mettre en place une politique QSE efficace

Les startups et la GMAO

Comment choisir son patch anti-ondes ?
