Gadgets
Une application Web pour extraire des informations clés d'articles de revues

Une capture d'écran du site Web DIVE. Crédit: Gupta et al.
Les articles académiques contiennent souvent des récits de nouvelles avancées et des théories intéressantes liées à une variété de domaines. Cependant, la plupart de ces articles sont rédigés dans un jargon et un langage technique qui ne peuvent être compris que par des lecteurs familiarisés avec ce domaine d'étude.
Les lecteurs non experts sont donc généralement incapables de comprendre les articles scientifiques, à moins qu’ils ne soient conçus et rendus plus accessibles par des tiers qui comprennent les concepts et les idées qu’ils contiennent. Dans cet esprit, une équipe de chercheurs du Texas Advanced Computing Center de l’Université du Texas à Austin (TACC), de l’Oregon State University (OSU) et de l’American Society of Plant Biologists (ASPB) a entrepris de mettre au point un outil qui peut extraire automatiquement des phrases importantes et la terminologie des documents de recherche afin de fournir des définitions utiles et d'améliorer leur lisibilité.
"Notre projet est motivé par le besoin d'améliorer la lisibilité des articles de journaux", a déclaré Weijia Xu, qui dirige l'équipe de TACC, à TechXplore. "C’est un effort commun des conservateurs biologiques, des éditeurs de revues et des informaticiens visant à développer un service Web capable de reconnaître et de permettre aux auteurs de conserver une terminologie importante utilisée dans les publications de revues. La terminologie et les mots sont ensuite joints à la fin de l’article de la revue afin d'accroître son accessibilité pour les lecteurs. "
Xu et ses collègues ont développé un cadre extensible qui peut être utilisé pour extraire des informations de documents. Ils ont ensuite implémenté ce cadre au sein d’un service Web appelé DIVE (Extraction de vocabulaire d’information de domaine), en l’intégrant au pipeline de publication de journal de l’ASPB. Contrairement aux outils existants pour l'extraction d'informations de domaine, leur cadre combine plusieurs approches, notamment l'extraction guidée par une ontologie, l'extraction basée sur des règles, le traitement du langage naturel et les techniques d'apprentissage approfondi.

La vue d'ensemble de l'architecture du système proposé par les chercheurs. Crédit: Gupta et al.
"Les résultats obtenus par différents modèles sont ensuite stockés dans une base de données centralisée", a expliqué Xu. "Nous avons également conçu un service Web qui permet aux utilisateurs de gérer les résultats d'extraction. Le service Web est intégré au pipeline de publication de production chez ASPB."
Une fois que la version préliminaire d'un article de revue est soumise et entre dans le pipeline de l'ASPB, le manuscrit est automatiquement transmis à DIVE, qui le traite et génère une URL avec laquelle l'auteur pourra accéder aux résultats du traitement de DIVE. L'auteur du document est invité à consulter le lien fourni et à passer en revue les informations extraites avant de pouvoir soumettre officiellement le document.
"L’auteur doit se rendre sur le site DIVE pour examiner les résultats de l’extraction et approuver définitivement la liste des informations à inclure à la fin de leur article", a déclaré Xu. "DIVE assure également le suivi des corrections apportées par les auteurs pour améliorer les futures tâches d'extraction. À l'heure actuelle, aucun autre éditeur de revues n'a adopté une approche similaire et ne l'a intégrée à son portefeuille de publications."
Lors de ses analyses et lors de l'extraction de données clés à partir de documents, le cadre développé par les chercheurs utilise plusieurs techniques. Cela lui permet de capturer plus d'informations que d'autres méthodes, telles que ABNER (un identificateur d'entité nommée biomédicale), qui est un outil logiciel open source pour l'exploration de texte en biologie moléculaire qui ne peut extraire que des termes généraux (par exemple, gènes et protéines). Contrairement à DIVE, ABNER repose uniquement sur les champs aléatoires conditionnels (CRF), méthode de modélisation statistique couramment utilisée dans les applications de reconnaissance de formes et d’apprentissage automatique.
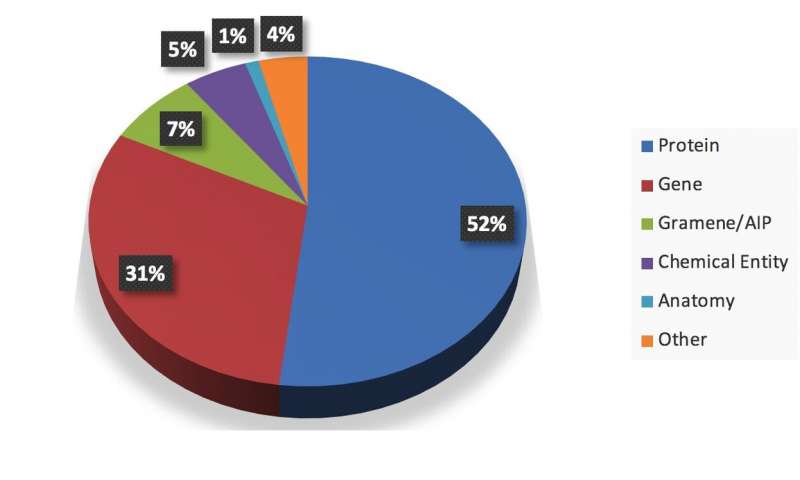
Résumé visuel d'un instantané des informations extraites par le système. Crédit: Gupta et al.
"Une contribution majeure de notre projet est qu'il aide à construire des ensembles de données et des modèles pouvant déduire les recherches des auteurs à partir de leurs publications", a déclaré Xu. "Notre projet peut bénéficier à des communautés plus larges de chercheurs en biologie. Pour les auteurs, l'extraction et l'inclusion d'informations clés peuvent accroître l'accessibilité de leurs articles."
Xu et son collègue Amit Gupta ont évalué leur cadre et comparé ses performances à celles d'autres outils d'extraction d'informations, notamment ABNER. Leurs résultats ont révélé que l'utilisation de plusieurs approches, y compris l'apprentissage en profondeur, permettait à DIVE d'obtenir des scores plus précis que d'autres modèles pré-formés basés uniquement sur des CRC. Il est intéressant de noter que le framework DIVE peut également être mis à jour en permanence, de nouveaux modèles d’extraction pouvant y être ajoutés à tout moment.
L'application Web DIVE ne permet pas seulement aux lecteurs non-experts de mieux comprendre les articles académiques, elle peut également les aider à identifier des articles correspondant à leurs intérêts. Les chercheurs, d’autre part, peuvent utiliser DIVE pour se tenir au courant de certains domaines de recherche, ainsi que pour se familiariser avec la nouvelle terminologie et les tendances en rapport avec leur domaine d’intérêt. Enfin, les informations générées par l'application peuvent également guider les conservateurs en biologie dans leurs décisions et leurs processus de collecte de données.
"Nous poursuivons notre projet en explorant deux directions", a déclaré Xu. "D'une part, nous étudions de nouvelles méthodes à incorporer dans nos modèles d'extraction d'informations pour améliorer les performances. D'autre part, nous essayons également d'étendre notre service en le proposant à d'autres communautés d'utilisateurs et à des éditeurs de revues."
Un système d'intelligence artificielle surfe sur le Web pour améliorer ses performances
Amit Gupta et al. Extraction d'informations de domaine à l'aide de l'apprentissage en profondeur, Actes de la pratique et de l'expérience de la recherche avancée en informatique sur la montée en puissance des machines (apprentissage) – PEARC '19 (2019). DOI: 10.1145 / 3332186.3332255
© 2019 Science X Network
Citation:
Une application Web permettant d'extraire des informations clés d'articles de revues (21 août 2019)
récupéré le 21 août 2019
de https://techxplore.com/news/2019-08-web-application-key-journal-articles.html
Ce document est soumis au droit d'auteur. Mis à part toute utilisation équitable à des fins d’étude ou de recherche privée, aucun
partie peut être reproduite sans autorisation écrite. Le contenu est fourni seulement pour information.
Sommaire
Les offres de produits Hi-tech en rapport avec cet article
Autres articles en relation:
 Google teste une nouvelle application appelée « Task Mate » pour collecter des informations commerciales et des enregistrements vocaux
Google teste une nouvelle application appelée « Task Mate » pour collecter des informations commerciales et des enregistrements vocaux
 Une étude révèle que les informations de restaurants en ligne peuvent permettre de prédire de près les indicateurs clés de voisinage
Une étude révèle que les informations de restaurants en ligne peuvent permettre de prédire de près les indicateurs clés de voisinage
 Cette application permet aux étrangers de trouver des informations sur vous en un clin d'œil
Cette application permet aux étrangers de trouver des informations sur vous en un clin d'œil
 Cette application de rencontres populaire a divulgué des informations sur des millions d'utilisateurs
Cette application de rencontres populaire a divulgué des informations sur des millions d'utilisateurs
 Revues en Amazonie Black Friday pour Echo, Kindle y Fire TV
Revues en Amazonie Black Friday pour Echo, Kindle y Fire TV
 VIDEO : Application de suivi gratuite pour smartphone pour Android – Guide d’installation complet et examen | Application d’espionnage gratuite de 2020
VIDEO : Application de suivi gratuite pour smartphone pour Android – Guide d’installation complet et examen | Application d’espionnage gratuite de 2020
 Résumé des revues Apple TV Plus: des émissions étoilées classées par la critique
Résumé des revues Apple TV Plus: des émissions étoilées classées par la critique
 Prêt pour les salles de bain intelligentes? Kohler dévoile une baignoire contrôlée par application
Prêt pour les salles de bain intelligentes? Kohler dévoile une baignoire contrôlée par application

Entreprise : 3 clés pour mettre en place une politique QSE efficace

Les startups et la GMAO

Comment choisir son patch anti-ondes ?
