Internet
Une nouvelle approche scientifique réduit les biais dans les données d’entraînement pour un meilleur apprentissage automatique

Gautam Thakur dirige une équipe de chercheurs de l’ORNL qui ont développé une nouvelle méthode scientifique pour identifier les biais dans les annotateurs de données humaines afin de garantir des entrées de données de haute qualité pour les applications d’apprentissage automatique. Crédit : Carlos Jones/ORNL, US Dept. of Energy
Alors que les entreprises et les décideurs se tournent de plus en plus vers l’apprentissage automatique pour donner un sens à de grandes quantités de données, il devient essentiel de garantir la qualité des données de formation utilisées dans les problèmes d’apprentissage automatique. Ces données sont codées et étiquetées par des annotateurs de données humains, souvent embauchés sur des plateformes de crowdsourcing en ligne, ce qui fait craindre que les annotateurs de données introduisent par inadvertance des biais dans le processus, réduisant finalement la crédibilité de la sortie de l’application d’apprentissage automatique.
Une équipe de scientifiques dirigée par Gautam Thakur du Oak Ridge National Laboratory a développé une nouvelle méthode scientifique pour détecter les biais des annotateurs de données humaines, garantissant des entrées de données de haute qualité pour les tâches d’apprentissage automatique. Les chercheurs ont également conçu une plate-forme en ligne appelée ThirdEye qui permet d’intensifier le processus de dépistage.
Les résultats de l’équipe ont été publiés dans le Résultats de l’Association for Computational Linguistics : ACL-IJCNLP 2021.
« Nous avons créé une méthode très systématique et très scientifique pour trouver de bons annotateurs de données », a déclaré Thakur. « Cette approche indispensable améliorera les résultats et le réalisme des décisions d’apprentissage automatique concernant l’opinion publique, les récits en ligne et la perception des messages. »
Le vote sur le Brexit à l’automne 2016 a permis à Thakur et à ses collègues Dasha Herrmannova, Bryan Eaton et Jordan Burdette et à leurs collaborateurs Janna Caspersen et Rodney « RJ » Mosquito de tester leur méthode. Ils ont étudié comment cinq mesures communes d’attitude et de connaissances pourraient être combinées pour créer un profil anonymisé d’annotateurs de données susceptibles d’étiqueter les données utilisées pour les applications d’apprentissage automatique de la manière la plus précise et la plus exempte de biais possible. Ils ont testé 100 annotateurs de données potentiels de 26 pays en utilisant plusieurs milliers de publications sur les réseaux sociaux à partir de 2019.
« Dites que vous voulez utiliser l’apprentissage automatique pour détecter de quoi les gens parlent. Dans le cas de notre étude, parlent-ils du Brexit d’une manière positive ou négative ? rester dans l’UE parce que leurs préjugés nuisent à leurs performances ? » dit Thakur. « Les annotateurs de données qui peuvent mettre de côté leurs propres croyances fourniront des étiquettes de données plus précises, et nos recherches aident à les trouver. »
La conception à méthodes mixtes des chercheurs filtre les annotateurs de données avec des mesures qualitatives – l’échelle de racisme symbolique 2000, le questionnaire sur les fondements moraux, le test des antécédents des médias sociaux, le test de connaissance du Brexit et les mesures démographiques – pour développer une compréhension de leurs attitudes et croyances. Ils ont ensuite effectué des analyses statistiques sur les annotateurs d’étiquettes attribués aux publications sur les réseaux sociaux contre un expert en la matière ayant une connaissance approfondie du Brexit et du climat géopolitique de la Grande-Bretagne et un spécialiste des sciences sociales expert en langage incendiaire et en propagande en ligne.
Thakur souligne que la méthode de l’équipe est évolutive de deux manières. Premièrement, il traverse des domaines, impactant la qualité des données pour les problèmes d’apprentissage automatique liés aux décisions en matière de transport, de climat et de robotique, en plus des soins de santé et des récits géopolitiques pertinents pour la sécurité nationale. Deuxièmement, ThirdEye, la plate-forme Web interactive open source de l’équipe, intensifie la mesure des attitudes et des croyances, permettant le profilage de groupes plus importants d’annotateurs de données potentiels et une identification plus rapide des meilleures embauches.
« Cette recherche indique fortement que la morale, les préjugés et la connaissance préalable du récit en question des annotateurs de données ont un impact significatif sur la qualité des données étiquetées et, par conséquent, sur les performances des modèles d’apprentissage automatique », a déclaré Thakur. « Les projets d’apprentissage automatique qui s’appuient sur des données étiquetées pour comprendre les récits doivent évaluer qualitativement la vision du monde de leurs annotateurs de données s’ils veulent faire des déclarations définitives sur leurs résultats. »
Les applications d’apprentissage automatique ont besoin de moins de données que prévu
Gautam Thakur et al, A Mixed-Method Design Approach for Empirically Based Selection of Unbiased Data Annotators, Résultats de l’Association for Computational Linguistics : ACL-IJCNLP 2021 (2021). DOI : 10.18653/v1/2021.findings-acl.169
Fourni par le Laboratoire national d’Oak Ridge
Citation: Une nouvelle approche scientifique réduit les biais dans les données de formation pour un meilleur apprentissage automatique (2021, 1er septembre) extrait le 2 septembre 2021 de https://techxplore.com/news/2021-09-scientific-approach-bias-machine.html
Ce document est soumis au droit d’auteur. En dehors de toute utilisation équitable à des fins d’étude ou de recherche privée, aucune partie ne peut être reproduite sans l’autorisation écrite. Le contenu est fourni seulement pour information.
Sommaire
Les offres de produits Hi-tech en rapport avec cet article
Autres articles en relation:
 Facebook dévoile un traducteur d’apprentissage automatique pour 100 langues
Facebook dévoile un traducteur d’apprentissage automatique pour 100 langues
 Utiliser une approche scientifique pour évaluer la valeur du temps de trajet
Utiliser une approche scientifique pour évaluer la valeur du temps de trajet
 Google lance un cadre d'apprentissage automatique pour la formation de modèles quantiques
Google lance un cadre d'apprentissage automatique pour la formation de modèles quantiques
 Le contexte réduit les biais raciaux dans les algorithmes de détection de discours de haine
Le contexte réduit les biais raciaux dans les algorithmes de détection de discours de haine
 Un chercheur utilise l’apprentissage automatique pour identifier les sautes d’humeur via les médias sociaux
Un chercheur utilise l’apprentissage automatique pour identifier les sautes d’humeur via les médias sociaux
 Les chercheurs utilisent l'apprentissage automatique pour dénicher des « pods '' souterrains d'Instagram
Les chercheurs utilisent l'apprentissage automatique pour dénicher des « pods '' souterrains d'Instagram
 Déjouer la fraude avec l'apprentissage automatique
Déjouer la fraude avec l'apprentissage automatique
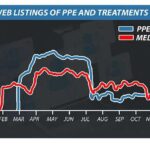 Un scientifique des données analyse l’évolution des marchés du dark web COVID-19 avant le vaccin
Un scientifique des données analyse l’évolution des marchés du dark web COVID-19 avant le vaccin

Entreprise : 3 clés pour mettre en place une politique QSE efficace

Les startups et la GMAO

Comment choisir son patch anti-ondes ?
