Internet
Une nouvelle stratégie pour identifier rapidement les trolls Twitter
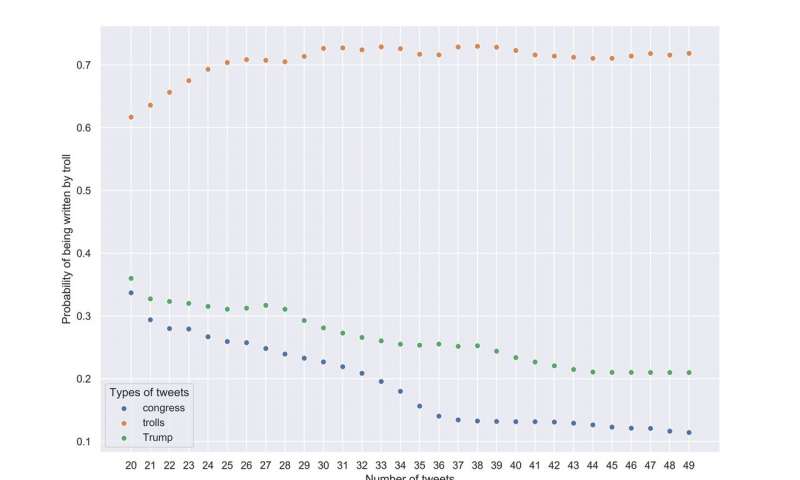
Congrès, trolls et tweets de Trump. Résultats de l'inférence bayésienne pour 50 tweets aléatoires. Crédit: Monakhov, 2020 (PLOS ONE, CC BY)
Deux algorithmes qui rendent compte de l'utilisation distinctive de mots répétés et de paires de mots ne nécessitent que 50 tweets pour distinguer avec précision les messages trompeurs «trolls» de ceux publiés par des personnalités publiques. Sergei Monakhov de l'Université Friedrich Schiller à Jena, en Allemagne, présente ces résultats dans la revue en libre accès PLOS ONE le 12 août 2020.
Les messages Internet Troll visent à atteindre un objectif spécifique, tout en masquant cet objectif. Par exemple, en 2018, 13 ressortissants russes ont été accusés d'avoir utilisé de faux personnages pour interférer avec l'élection présidentielle américaine de 2016 via des publications sur les réseaux sociaux. Alors que des recherches antérieures ont examiné les caractéristiques distinctives des tweets de troll – telles que le timing, les hashtags et la localisation géographique – peu d'études ont examiné les caractéristiques linguistiques des tweets eux-mêmes.
Monakhov a adopté une approche sociolinguistique, se concentrant sur l'idée que les trolls ont un nombre limité de messages à transmettre, mais doivent le faire plusieurs fois et avec suffisamment de diversité de mots et de sujets pour tromper les lecteurs. En utilisant une bibliothèque de tweets de trolls russes et de vrais tweets de membres du Congrès américain, Monakhov a montré que ces restrictions spécifiques aux trolls entraînaient des modèles distinctifs de mots répétés et de paires de mots qui diffèrent des modèles observés dans les tweets authentiques et non trolls.
Ensuite, Monakhov a testé un algorithme qui utilise ces modèles distinctifs pour faire la distinction entre les vrais tweets et les tweets trolls. Il a constaté que l'algorithme ne nécessitait que 50 tweets pour une identification précise des trolls par rapport aux membres du Congrès. Il a également constaté que l'algorithme distinguait correctement les tweets de trolls des tweets de Donald Trump – qui, bien que provocants et «potentiellement trompeurs», selon Twitter, ne sont pas conçus pour cacher son objectif.
Cette nouvelle stratégie d'identification rapide des tweets de trolls pourrait contribuer à éclairer les efforts de lutte contre la guerre hybride tout en préservant la liberté d'expression. Des recherches supplémentaires seront nécessaires pour déterminer s'il peut distinguer avec précision les tweets trolls d'autres types de messages qui ne sont pas publiés par des personnalités publiques.
Monakhov ajoute: «Bien que l'écriture des trolls soit généralement considérée comme imprégnée de messages récurrents, son trait le plus caractéristique est une distribution anormale de mots et de paires de mots répétés. En utilisant le rapport de leurs proportions comme mesure quantitative, il suffit de 50 douces pour identifier comptes de troll Internet. "
Les utilisateurs de Twitter peuvent avoir changé leur comportement après un contact avec des trolls russes
Monakhov S (2020) Détection précoce des trolls Internet: introduction d'un algorithme basé sur le rapport de répétition multiple de paires de mots / mots simples. PLoS ONE 15 (8): e0236832. doi.org/10.1371/journal.pone.0236832
Citation:
Une nouvelle stratégie pour identifier rapidement les trolls Twitter (12 août 2020)
récupéré le 12 août 2020
depuis https://techxplore.com/news/2020-08-strategy-quickly-twitter-trolls.html
Ce document est soumis au droit d'auteur. En dehors de toute utilisation équitable à des fins d'étude ou de recherche privées, aucune
une partie peut être reproduite sans autorisation écrite. Le contenu est fourni seulement pour information.
Sommaire
Les offres de produits Hi-tech en rapport avec cet article
Autres articles en relation:
 Twitter teste le mode sécurisé pour bloquer les trolls sur Internet
Twitter teste le mode sécurisé pour bloquer les trolls sur Internet
 Les utilisateurs de Twitter peuvent avoir changé leur comportement après un contact avec des trolls russes
Les utilisateurs de Twitter peuvent avoir changé leur comportement après un contact avec des trolls russes
 Les utilisateurs les plus en vue de Twitter bénéficient d’un traitement VIP lorsque les trolls frappent
Les utilisateurs les plus en vue de Twitter bénéficient d’un traitement VIP lorsque les trolls frappent
 Les trolls politiques s'adaptent, créent du matériel pour tromper et embrouiller le public
Les trolls politiques s'adaptent, créent du matériel pour tromper et embrouiller le public
 Twitter ajoute une option pour partager des tweets parlés
Twitter ajoute une option pour partager des tweets parlés
 La recherche peut aider Twitter à fonctionner plus rapidement
La recherche peut aider Twitter à fonctionner plus rapidement
 Les artistes Twitter adoreront cette nouvelle option d’image
Les artistes Twitter adoreront cette nouvelle option d’image

Entreprise : 3 clés pour mettre en place une politique QSE efficace

Les startups et la GMAO

Comment choisir son patch anti-ondes ?
